|
|
|
|
|
Аудит "здоровья" сети своими силамиВыявление явных проблем сети
|
 |
Методика выявления явных проблем относительно проста. Поскольку явные проблемы всегда "оставляют следы", то чтобы их локализовать, достаточно иметь средство мониторинга, позволяющее "увидеть эти следы". "Увидеть следы" - это найти метрики, значения которых больше или меньше рекомендуемых (пороговых) значений. Это является признаком наличия проблемы.
|
|
|
|
Если сетевое оборудования поддерживает SNMP, то для его мониторинга чаще всего используют SNMP-консоль (SNMP, Simple Network Management Protocol). Это специальная программа, которая периодически обращается к агенту (SNMP-агенту), встроенному в оборудование, и забирает значения метрик, которые этот агент измеряет. Использование SNMP-консоли позволяет выявить множество явных сетевых проблем. К ним относятся, например, ошибки передачи данных, вызываемые дефектами кабельной системы сети и/или неправильной настройкой коммутаторов (на одном конце линка - full duplex, на другом конце - half duplex). Широковещательные штормы, блокирующие работу портов сетевого устройства. Высокая утилизация портов коммутатора, переполнение таблиц коммутации, утечка памяти на маршрутизаторах и многое другое. Большинство SNMP-консолей можно эффективно использовать также для мониторинга Linux-серверов, периферийного оборудования, источников бесперебойного питания, баз данных и много другого.
|
|
|
|
Для мониторинга серверов MS Windows обычно используют утилиту MS Performance Monitor или WMI-консоли других производителей (WMI - Windows Management Interface). Подобные средства позволяют выявить большинство явных проблем, связанных с работой Windows-серверов. Чаше всего это высокая утилизация процессоров, низкий процент кэшируемых данных, очереди в дисковой системе, утечка ОЗУ и т.п. Кроме этого, многие бизнес-приложения добавляют свои счетчики в MS Performance Monitor, поэтому с помощью этих средств можно контролировать еще и работу бизнес-приложений.
|
|
|
|
Если нужно провести аудит "здоровья" небольшой сети (10-50 компьютеров), то возможностей обычного средства мониторинга для этого, как правило, вполне достаточно. Если же необходимо провести аудит сети, состоящей из ста и более компьютеров, то использование обычных средств мониторинга сопряжено с рядом сложностей.
|
|
|
|
Первой сложностью является необходимость одновременного измерения большого числа метрик. Например, чтобы измерить качество работы сети, состоящей только из одного 48-портового коммутатора, нужно измерить, как минимум, значения 144 метрик (48 метрик - ошибки по портам, 48 метрик - процент широковещательных пакетов, 48 метрик - утилизация портов). Если сеть состоит из пяти таких коммутаторов, то нужно будет измерить уже 720 метрик. Но кроме коммутаторов в сети есть еще серверы, маршрутизаторы, сетевые экраны и другие устройства, качество работы которых нужно измерять. С помощью обычных средств мониторинга это сложно сделать по двум причинам. Во-первых, нужно знать, какие метрики нужно измерять в каждом конкретном случае. Во-вторых, нужно проделать большую работу, чтобы настроить средство мониторинга на автоматическое получение всех этих метрик.
|
|
|
|
Вторая сложность заключается в том, что значения всех метрик нужно не только получить, но и правильно оценить. Если оценить метрики, характеризующие работу простейшего коммутатора Ethernet относительно несложно, то оценить метрики, характеризующие работу серверов, баз данных, маршрутизаторов, сетевых экранов и т.п. значительно сложнее. Обычно, чем качественнее сетевое оборудование, тем больше информации о себе оно предоставляет. В этом, кстати, одно из различий дорогого и дешевого оборудования. Если дорогой коммутатор позволяет узнать о себе практически все (начиная с исправности вентилятора и заканчивая утилизацией таблицы коммутации), то дешевый коммутатор в лучшем случае предоставляет информацию об интенсивности трафика и числе ошибок на портах, а иногда и этого не делает.
|
|
|
|
Для проведения аудита "здоровья" больших сетей нужно использовать специализированный инструментарий. Только в этом случае получение данных, на основе которых можно сделать достоверные выводы о "здоровье" ИТ-Инфраструктуры, является выполнимой задачей. Примером такого инструментария, является бесплатный программный продукт QuTester Plus. Этот продукт отличается от обычных средств мониторинга наличием встроенных Оценочных Тестов (ProLAN-Тестов), позволяющих существенно упростить процесс сбора и оценки метрик "здоровья" ИТ-Инфраструктуры. ProLAN: Тесты - это программы на скриптовом языке, в которых предустановленно, какие метрики и как должны измеряться для оценки качества работы различных компонент сети (коммутаторов, маршрутизаторов, серверов, каналов связи и т.д.), а также пороговые значения для каждой измеряемой метрики. ProLAN-тест является упрощенной экспертной системой, предназначенной для оценки "здоровья" различных компонент ИТ-Инфраструктуры.
|
|
|
|
Всего компанией ProLAN разработано более 40 ProLAN-Тестов, из них более 20 являются бесплатными продуктами и поставляются в составе QuTester Plus. В данной статье мы будем рассматривать только такие тесты.
|
|
|
|
Для выявления явных дефектов и "узких мест" ИТ-Инфраструктуры рекомендуется использовать тесты, перечисленные в Таблице 1. Эти тесты мы называем пассивными, т.к. они не измеряют значения метрик, а получают их от контролируемых устройств.
Таблица 1.
|
Объекты аудита |
|
Рекомендуемые ProLAN: Тесты |
|
Коммутаторы и любое сетевое оборудование, поддерживающее SNMP MIB II (маршрутизаторы, сетевые карты, сетевые экраны, Linux-серверы и т.п.) |
|
Профессиональный тест оценки "здоровья" коммутаторов, поддерживающих MIB II. |
|
Коммутаторы |
|
Профессиональный тест оценки "здоровья" коммутаторов, поддерживающих MIB II.
Тест контроля утилизации таблиц коммутации (802.1D) |
|
Серверы MS Windows |
|
Тест оценки "здоровья" сервера NT4/2000/XP.
Тест оценки "здоровья" сервера MS SQL.
Тест оценки "здоровья" сервера MS DNS. |
|
Маршрутизаторы Cisco Systems |
|
Tест оценки "здоровья" маршрутизаторов Cisco. |
|
|
|
|
|
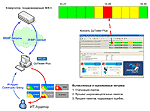
Описания этих тестов можно найти в разделе ProLAN: Тесты или в бесплатно распространяемом справочнике Test IT; см. раздел: "За Качество IP-Сетей". Методику работы с оценочными тестами рассмотрим на примере использования профессионального теста оценки "здоровья" коммутаторов, поддерживающих MIB II (см. Рисунок 1).
|
|
|
|
На любой (не обязательно выделенный) компьютер сети установите программный пакет QuTester Plus и стартуйте его в режиме ProLAN-Administrator (Demo). Из предложенного списка запустите профессиональный тест оценки "здоровья" коммутаторов, поддерживающих MIB II. Этот тест находится в группе, которая называется: "Тесты оценки здоровья оборудования, поддерживающего SNMP". Вам будет предложено задать IP-адрес тестируемого коммутатора и пароль (community string) для доступа по чтению. Дальше все делается автоматически. Тест сам подключится к коммутатору, определит его модель, число портов, производительность портов, проверит, поддерживает ли коммутатор MIB II и т.п. После окончания проверок тест начнет получать SNMP-данные, характеризующие работу сети (число принятых байт, число переданных байт, число широковещательных пакетов, число ошибок и т.д.).
|
|
|
|
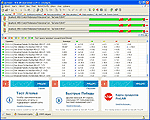
Каждую минуту для каждого порта коммутатора тест будет автоматически вычислять значения трех метрик: утилизация порта, процент широковещательных пакетов, процент ошибок. Все эти метрики каждую минуту будут автоматически сравниваться с предустановленными пороговыми значениями, и оцениваться по пятибалльной шкале (пороговые значения можно изменять). В результате каждую минуту тест будет формировать набор цветных индикаторов, характеризующих текущее "здоровье" сети. Наихудшее значение индикатора выводится на ленточную диаграмму, которая называется светофором. Если ни одна метрика в течение данной минуты не превысила пороговое значение, то светофор будет зеленым. Если хотя бы одна метрика превысит пороговое значение, то светофор изменит свой цвет. Под светофором отображается его расшифровка, представляющая собой список метрик, из которых состоит светофор и результаты их оценки (см. Рисунок 2).
|
|
|
|
Поскольку тест должен работать в течение длительного периода времени, вам следует настроить систему оповещения о сбоях. Если это сделать, то тест будет автоматически посылать электронные письма всякий раз, когда цвет светофора изменится. При этом можно задать цвета светофоров и сколько раз подряд такое изменение должно произойти, прежде чем будет отправлено письмо. В письме содержится информация о том, какой светофор изменил свой цвет, когда это произошло, какие метрики при этом изменились и насколько. Каждое такое письмо является тем самым "следом", который оставляет явный дефект или "узкое место" сети. Множество таких писем будем называть логом явных проблем.
|
|
|
|
Анализировать лог явных проблем не сложно, т.к. в описании каждой метрики, как правило, содержится информация о возможных причинах дефекта. Например, причинами большого числа ошибок передачи данных в 100% коммутируемой сети обычно являются: дефекты кабельной системы, дефекты приемо-передающего оборудования, неправильная настройка портов коммутаторов (на одном конце линка - full duplex, на другом конце - half duplex). Причиной высокой утилизации порта может быть неудачная топология сети, использование в сети большого числа ресурсоемких приложений (передача живого видео), неправильная настройка порта коммутатора. Наличие большого числа широковещательных пакетов, как правило, объясняется использованием в сети соответствующих приложений. Если что-то из перечисленного не является, по вашему мнению, проблемой, то вы можете уменьшить число оцениваемых метрик (например, не оценивать процент широковещательных пакетов), или изменить пороговые значения.
|
 |
наверх
|
|